前言
base64编码是经常用到的一种编码,但以往我在使用它时只是单纯使用工具去进行编码和解码,没有去了解它们具体的编码和解码原理,今天特意抽出时间来学习一下。
base64
为什么要使用base64?
因为有些网络传送渠道并不支持所有的字节,例如传统的邮件只支持可见字符的传送,像ASCII码的控制字符就 不能通过邮件传送。这样用途就受到了很大的限制,比如图片二进制流的每个字节不可能全部是可见字符,所以就传送不了。最好的方法就是在不改变传统协议的情 况下,做一种扩展方案来支持二进制文件的传送。把不可打印的字符也能用可打印字符来表示,问题就解决了。Base64编码应运而生,Base64就是一种 基于64个可打印字符来表示二进制数据的表示方法。
base64编码原理
看一下Base64的索引表,字符选用了”A-Z、a-z、0-9、+、/” 64个可打印字符。数值代表字符的索引,这个是标准Base64协议规定的,不能更改。
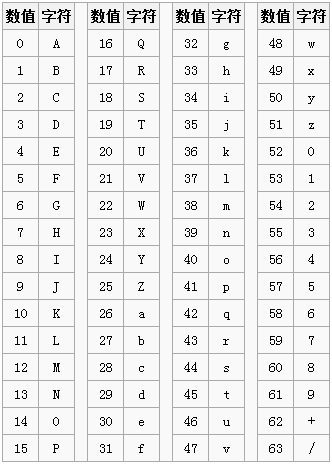 在日常使用中我们还会看到“=”或“==”号出现在Base64的编码结果中,“=”在此是作为填充字符出现,后面会讲到。
在日常使用中我们还会看到“=”或“==”号出现在Base64的编码结果中,“=”在此是作为填充字符出现,后面会讲到。
具体转化步骤
1.将待转换的字符串每三个字节分为一组,每个字节占8bit,那么共有24个二进制位。
2.将上面的24个二进制位每6个一组,共分为4组。
3.在每组前面添加两个0,每组由6个变为8个二进制位(即一个字节),总共32个二进制位,即四个字节。
4.根据Base64编码对照表(见上图)获得对应的值。
其实这种转化也就是我们用四个base64的字符来表示3个原始的字符,在6之前补零的目的是让让它补到一个完整的8位字符即一个字节。因为我们用4个base64字节来表示原来的3个字节,所以使用base64编码后的字符串长度会变成原来的4/3。
举例说明
1.“M”、“a”、”n”对应的ASCII码值分别为77,97,110,对应的二进制值是01001101、01100001、01101110。如图第二三行所示,由此组成一个24位的二进制字符串。
2.如图红色框,将24位每6位二进制位一组分成四组。
3.在上面每一组前面补两个0,扩展成32个二进制位,此时变为四个字节:00010011、00010110、00000101、00101110。分别对应的值(Base64编码索引)为:19、22、5、46。
4.用上面的值在Base64编码表中进行查找,分别对应:T、W、F、u。因此“Man”Base64编码之后就变为:TWFu。
位数不足情况
上面是按照三个字节来举例说明的,如果字节数不足三个,那么该如何处理?
两个字节:两个字节共16个二进制位,依旧按照规则进行分组。此时总共16个二进制位,每6个一组,则第三组缺少2位,用0补齐,得到三个Base64编码,第四组完全没有数据则用“=”补上。因此,上图中“BC”转换之后为“QKM=”
一个字节:一个字节共8个二进制位,依旧按照规则进行分组。此时共8个二进制位,每6个一组,则第二组缺少4位,用0补齐,得到两个Base64编码,而后面两组没有对应数据,都用“=”补上。因此,上图中“A”转换之后为“QQ==”;
中文如何进行base64编码?
再举一个中文的例子,汉字”严”如何转化成Base64编码?
这里需要注意,汉字本身可以有多种编码,比如gb2312、utf-8、gbk等等,每一种编码的Base64对应值都不一样。下面的例子以utf-8为例。
首先,”严”的utf-8编码为E4B8A5,写成二进制就是三字节的”11100100 10111000 10100101”。将这个24位的二进制字符串,按照第3节中的规则,转换成四组一共32位的二进制值”00111001 00001011 00100010 00100101”,相应的十进制数为57、11、34、37,它们对应的Base64值就为5、L、i、l。
所以,汉字”严”(utf-8编码)的Base64值就是5Lil。
python中如何进行对base64的编解码
Python已经内置了一个用于Base64编解码的库:base64。编码使用base64.b64encode()方法,解码使用base64.b64decode()方法。
>>> import base64
>>> str = 'hello world'
>>>
>>> base64_str = base64.b64encode(str)
>>> print base64_str
aGVsbG8gd29ybGQ=
>>>
>>> ori_str = base64.b64decode(base64_str)
>>> print ori_str
hello world
拓展
base64编码是用64(2的6次方)个ASCII字符来表示256(2的8次方)个ASCII字符,也就是三位二进制数组经过编码后变为四位的ASCII字符显示,长度比原来增加1/3。
同样,base32就是用32(2的5次方)个特定ASCII码来表示256个ASCII码。所以,5个ASCII字符经过base32编码后会变为8个字符(公约数为40),长度增加3/5.
base16就是用16(2的4次方)个特定ASCII码表示256个ASCII字符。1个ASCII字符经过base16编码后会变为2个字符,长度增加一倍。
同样python的base64库也可以进行base32/16的编码和解码。
base64.b16decode
base64.b32decode
CTF实战
当我们理解了base64的原理后变可以解决一些base64变形的编码题目了。以moectf一道题目为例,题目给出了:
ciphertext
hcw0eqM1kpDnipblhcAQiowWiYI9jAwWNdjWkdIlIpW0dqIWhcbw
table
xyUVzABCDEFGHIJKLMNOabcdefghijklmWXYZ0123456789PQRSTnopqrstuvw+/=
可以看出题目是将base64的64个字符进行了重新编排顺序而已,理解了原理以后,我们可以写出脚本:
tables = "xyUVzABCDEFGHIJKLMNOabcdefghijklmWXYZ0123456789PQRSTnopqrstuvw+/=" # 65
ciphertext = "hcw0eqM1kpDnipblhcAQiowWiYI9jAwWNdjWkdIlIpW0dqIWhcbw" # 52
for i in range(0,52,4):
# 4个字符一组,1个字符算1个字节
substr = ciphertext[i:i+4]
bin_str = ""
for j in substr:
# 每个字节换成ASCII,去掉00,补齐6位
# 总共拼接成 24位,
bin_str += bin(tables.index(j))[2:].zfill(6)
# 分割成3字节,从tables中找对应字符
print(chr(int(bin_str[:8], 2)),end='')
print(chr(int(bin_str[8 :16], 2)),end='')
print(chr(int(bin_str[16:24], 2)),end='')
# moectf{b4se_maps_ar3nt_aIways_7he_same}